I’ve just uploaded to the arXiv my paper “Local Bernstein theory, and lower bounds for Lebesgue constants“. This paper was initially motivated by a problem of Erdős} on Lagrange interpolation, but in the course of solving that problem, I ended up modifying some very classical arguments of Bernstein and his contemporaries (Boas, Duffin, Schaeffer, Riesz, etc.) to obtain “local” versions of these classical “Bernstein-type inequalities” that may be of independent interest.
Bernstein proved many estimates concerning the derivatives of polynomials, trigonometric polynomials, and entire functions of exponential type, but perhaps his most famous inequality in this direction is:
Lemma 1 (Bernstein’s inequality for trigonometric polynomials) Let  be a trigonometric polynomial of degree at most
be a trigonometric polynomial of degree at most  , with
, with 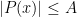 for all
for all  . Then
. Then  for all .
for all .
Similar inequalities concerning  norms of derivatives of Littlewood-Paley components of functions are now ubiquitious in the modern theory of nonlinear dispersive PDE (where they are also called Bernstein estimates), but this will not be the focus of this current post.
norms of derivatives of Littlewood-Paley components of functions are now ubiquitious in the modern theory of nonlinear dispersive PDE (where they are also called Bernstein estimates), but this will not be the focus of this current post.
A trigonometric polynomial  of degree is of exponential type in the sense that
of degree is of exponential type in the sense that  for complex
for complex  . Bernstein in fact proved a more general result:
. Bernstein in fact proved a more general result:
Lemma 2 (Bernstein’s inequality for functions of exponential type) Let  be an entire function of exponential type at most
be an entire function of exponential type at most  , with
, with  for all
for all 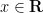 . Then
. Then  for all .
for all .
There are several proofs of this lemma – see for instance this survey of Queffélec and Zarouf. In the case that  is real-valued on
is real-valued on  , there is a nice proof by Duffin and Schaeffer, which we sketch as follows. Suppose we normalize
, there is a nice proof by Duffin and Schaeffer, which we sketch as follows. Suppose we normalize  , and adjust by a suitable damping factor so that
, and adjust by a suitable damping factor so that  actually decays slower than
actually decays slower than  as
as 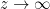 . Then, for any
. Then, for any  and
and  , one can use Rouche’s theorem to show that the function
, one can use Rouche’s theorem to show that the function  has the same number of zeroes as
has the same number of zeroes as  in a suitable large rectangle; but on the other hand one can use the intermediate value theorem to show that has at least as many zeroes than in the same rectangle. Among other things, this prevents double zeroes from occuring, which turns out to give the desired claim
in a suitable large rectangle; but on the other hand one can use the intermediate value theorem to show that has at least as many zeroes than in the same rectangle. Among other things, this prevents double zeroes from occuring, which turns out to give the desired claim  after some routine calculations (in fact one obtains the stronger bound
after some routine calculations (in fact one obtains the stronger bound  for all real ).
for all real ).
The first main result of the paper is to obtain localized versions of Lemma 2 (as well as some related estimates). Roughly speaking, these estimates assert that if is holomorphic on a wide thin rectangle passing through the real axis, is bounded by  on the intersection of the real axis with this rectangle, and is “locally of exponential type” in the sense that it is bounded by
on the intersection of the real axis with this rectangle, and is “locally of exponential type” in the sense that it is bounded by  on the upper and lower edges of this rectangle (and obeys some very mild growth conditions on the remaining sides of this rectangle), then
on the upper and lower edges of this rectangle (and obeys some very mild growth conditions on the remaining sides of this rectangle), then  can be bounded by
can be bounded by 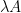 plus small errors on the real line, with some additional estimates away from the real line also available. The proof proceeds by a modification of the Duffin–Schaeffer argument, together with the two-constant theorem of Nevanlinna (and some standard estimates of harmonic measures on rectangles) to deal with the effect of the localization. (As a side note, this latter argument was provided to me by ChatGPT, as I was not previously aware of the Nevanlinna two-constant theorem.)
plus small errors on the real line, with some additional estimates away from the real line also available. The proof proceeds by a modification of the Duffin–Schaeffer argument, together with the two-constant theorem of Nevanlinna (and some standard estimates of harmonic measures on rectangles) to deal with the effect of the localization. (As a side note, this latter argument was provided to me by ChatGPT, as I was not previously aware of the Nevanlinna two-constant theorem.)
Once one localizes this “Bernstein theory”, it becomes suitable for the analysis of (real-rooted, monic) polynomials of a high degree , which are not bounded globally on (and grow polynomially rather than exponentially at infinity), but which can exhibit “local exponential type” behavior on various intervals, particularly in regions where the logarithmic potential

behaves like a smooth function (here

is the empirical measure of the roots

of
). A key example is the (monic) Chebyshev polynomials

, which locally behave like sinusoids on the interval
![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
(and are locally of exponential type above and below this interval):

This becomes relevant in the theory of Lagrange interpolation. Recall that if  are real numbers and
are real numbers and  is a polynomial of degree less than then one has the interpolation formula
is a polynomial of degree less than then one has the interpolation formula

where the Lagrange basis functions

are defined by the formula

In terms of the monic polynomial

, we can write

The stability and convergence properties of Lagrange interpolation are closely related to the
Lebesgue function 
and for a given interval

, the quantity

is known as the
Lebesgue constant for that interval.
If one chooses the interpolation points poorly, then the Lebesgue constant can be extremely large. However, if one selects these points to be the roots of the aforementioned monic Chebyshev polynomials, then it is known that  for all fixed intervals in . In the case
for all fixed intervals in . In the case ![{I = [-1,1]}](https://s0.wp.com/latex.php?latex=%7BI+%3D+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , it was shown by Erdős} that this is the best possible value of the Lebesgue constant up to
, it was shown by Erdős} that this is the best possible value of the Lebesgue constant up to  errors for interpolation on , thus
errors for interpolation on , thus
![\displaystyle \sup_{x \in [-1,1]} \Lambda(x) \geq \frac{2}{\pi} \log n - O(1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%7Bx+%5Cin+%5B-1%2C1%5D%7D+%5CLambda%28x%29+%5Cgeq+%5Cfrac%7B2%7D%7B%5Cpi%7D+%5Clog+n+-+O%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
whenever

(a more precise bound was
later shown by Vertesi). Erdős and Turán
then asked if the same lower bound

held for more general intervals
. This is shown in our paper; a variant integral bound

is also established, answering a separate question of Erdős. These lower bounds had previously obtained up to constants
by Erdős and Szabados}; the main issue was to obtain the sharp constant in the main term.
In terms of the monic polynomial , these two estimates can be written as

and

Using the intuition that
should behave locally like a trigonometric polynomial, and performing some renormalizations, one can extract the following toy problem to work with first:
Problem 3 Let 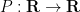 be a trigonometric polynomial of degree with
be a trigonometric polynomial of degree with  roots
roots  in
in  .
.
- (i) Show that

- (ii) Show that

It is easy to check that the lower bounds of  and
and 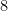 are sharp by considering the case when is a sinusoid
are sharp by considering the case when is a sinusoid  .
.
The bound (3) is immediate from Bernstein’s inequality (Lemma 1). By applying a local version of this inequality, I was able to get a weak version of the claim (1) in which was replaced with 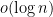 ; see this early version of the paper, which was developed through conversations with Nat Sothanaphan and Aron Bhalla. By combining this argument with ideas from the older work of Erdős}, I was able to establish (1).
; see this early version of the paper, which was developed through conversations with Nat Sothanaphan and Aron Bhalla. By combining this argument with ideas from the older work of Erdős}, I was able to establish (1).
The bound (2) took me longer to establish, and involved a non-trivial amount of playing around with AI tools, the story of which I would like to share here. I had discovered the toy problem (4), but initially was not able to establish this inequality; AlphaEvolve seemed to confirm it numerically (with sinusoids appearing to be the extremizer), but did not offer direct clues on how to prove this rigorously. At some point I realized that the left-hand side factorized into the expressions  and
and  , and tried to bound these expressions separately. Perturbing around a sinusoid
, and tried to bound these expressions separately. Perturbing around a sinusoid  , I was able to show that the
, I was able to show that the 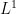 norm was a local minimum as long as one only perturbed by lower order Fourier modes, keeping the frequency coefficients unchanged. Guessing that this local minimum was actually a global minimum, this led me to conjecture the general lower bound
norm was a local minimum as long as one only perturbed by lower order Fourier modes, keeping the frequency coefficients unchanged. Guessing that this local minimum was actually a global minimum, this led me to conjecture the general lower bound

whenever
was a degree
trigonometric polynomial with highest frequency components

.
AlphaEvolve numerically confirmed this inequality to be likely to be true also. I still did not see how to prove this inequality, but I decided to try my luck
giving it to ChatGPT Pro, which recognized it as an
approximation problem and gave me a duality-based proof (based ultimately on the Fourier expansion of the square wave). With some further discussion, I was able to adapt this proof to functions of global exponential type (replacing the Fourier manipulations with contour shifting arguments, in the spirit of the Paley-Wiener theorem), which roughly speaking gave me half of what I needed to establish
(2). However, I still needed the matching lower bound

on the other factor in the toy problem. Again, AlphaEvolve could
numerically confirm that this inequality was likely to be true, but now the quantity I was trying to control did not look convex or linear in
, and so the previous duality method did not seem to apply. At this point I switched to pen and paper; eventually I realized that the expression almost looked like a sum of residues, and eventually after playing around with contour integrals of

using the residue theorem I was able to establish
(4), and then with a bit more (human) effort I could move from the toy problem back to the original problem to obtain
(2). Quite possibly AI tools would also have been able to assist with these steps, but they were not necessary here; their main value for me was in quickly confirming that the approach I had in mind was numerically plausible, and in recognizing the right technique to solve one part of the toy problem I had isolated. (I also used AI tools for several other secondary tasks, such as literature review, proofreading, and generating pictures, but these applications of AI have matured to the point where using them for this purpose is almost mundane.)


 and
and  are positive integers. Writing
are positive integers. Writing  , one can rewrite this equation as
, one can rewrite this equation as 
 denotes the squarefree part of
denotes the squarefree part of 
 to the original equation.
to the original equation.


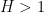









 .
.

is
of the number of bad points up to
.
.








 . The number of solutions here turns out to be
. The number of solutions here turns out to be  by work of Aktas-Murty and of Chan; we generalize the arguments in the former to handle a slightly more general equation. A similar argument handles solutions to (1), except in one regime where the parameter
by work of Aktas-Murty and of Chan; we generalize the arguments in the former to handle a slightly more general equation. A similar argument handles solutions to (1), except in one regime where the parameter  is somewhat large (comparable to
is somewhat large (comparable to  ), in which case one instead collects some congruence conditions on
), in which case one instead collects some congruence conditions on  and applies the large sieve.
and applies the large sieve.


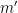



 is a binary operation such that
is a binary operation such that  for all
for all 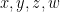 . Is it true that
. Is it true that  for all
for all 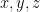 ?
?  , the constant in a certain autocorrelation quantity relating to Sidon sets
, the constant in a certain autocorrelation quantity relating to Sidon sets , the constant
, the constant (or some subinterval of the integers) and remove some congruence classes
(or some subinterval of the integers) and remove some congruence classes  for various moduli
for various moduli 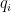 . Here we shall concern ourselves with the simple setting where we are sieving the entire integers rather than an interval, and are only removing a finite number of congruence classes
. Here we shall concern ourselves with the simple setting where we are sieving the entire integers rather than an interval, and are only removing a finite number of congruence classes  . In this case, the set of integers that remain after the sieving is periodic with period
. In this case, the set of integers that remain after the sieving is periodic with period  , so one work without loss of generality in the cyclic group
, so one work without loss of generality in the cyclic group 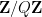 . One can then ask: what is the density of the sieved set
. One can then ask: what is the density of the sieved set 

 , the density of the sieved set is maximized when all the
, the density of the sieved set is maximized when all the  vanish. Thus,
vanish. Thus, 

 ,
,  , and
, and  , then only
, then only  remains, giving a density of
remains, giving a density of  . On the other hand, if one sieves out
. On the other hand, if one sieves out  ,
,  , and
, and  and
and  , giving the larger density of
, giving the larger density of  .
.  , with residue classes now becoming cosets of various subgroups of
, with residue classes now becoming cosets of various subgroups of  be cosets of a finite cyclic abelian group
be cosets of a finite cyclic abelian group 
 ,
,  ,
,  , and
, and  . Then the cosets
. Then the cosets  ,
,  , and
, and  cover the residues
cover the residues  , with a cardinality of
, with a cardinality of 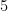 ; but the subgroups
; but the subgroups 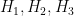 cover the residues
cover the residues  , having the smaller cardinality of
, having the smaller cardinality of  .
.  together reduces the total amount of space that these cosets occupy. As pointed out in comments, the requirement of cyclicity is crucial; four lines in a finite affine plane already suffice to be a counterexample otherwise.
together reduces the total amount of space that these cosets occupy. As pointed out in comments, the requirement of cyclicity is crucial; four lines in a finite affine plane already suffice to be a counterexample otherwise.
 -groups, Rogers’ theorem is an immediate consequence of two observations:
-groups, Rogers’ theorem is an immediate consequence of two observations:
 for some prime power
for some prime power 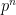 .
.  of coprime orders, then it also holds for the product
of coprime orders, then it also holds for the product  .
.  is simply the largest of the
is simply the largest of the 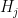 , which has the same size as
, which has the same size as  and thus has lesser or equal cardinality to
and thus has lesser or equal cardinality to  .
.
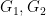 and standard group theoretic arguments (e.g.,
and standard group theoretic arguments (e.g.,  of subgroups of
of subgroups of 
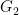 to each “vertical slice” of
to each “vertical slice” of 
 to each “horizontal slice” of
to each “horizontal slice” of 
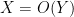 or
or 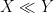 , for instance, to indicate a bound of the form
, for instance, to indicate a bound of the form  for some unspecified constant
for some unspecified constant 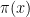 is asymptotic to the logarithmic integral
is asymptotic to the logarithmic integral  , in
, in 
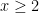 .
.

Recent Comments